hdinsight.github.io
Extended Spark History Server is built on top of the community version of Spark History Server and provide advanced features. The current extension includes data tab and graph tab. Data tab shows the input/output data source of the Spark job including table operations. This allows users to validate the output, preview input schema/data to facilitate the development. Graph tab provides job graph, playback and heatmap. This helps users to understand the bottleneck, monitor and diagonose issues. Please check Extended Spark UI documentation for detail information.
1. Hotfix extended Spark History Server
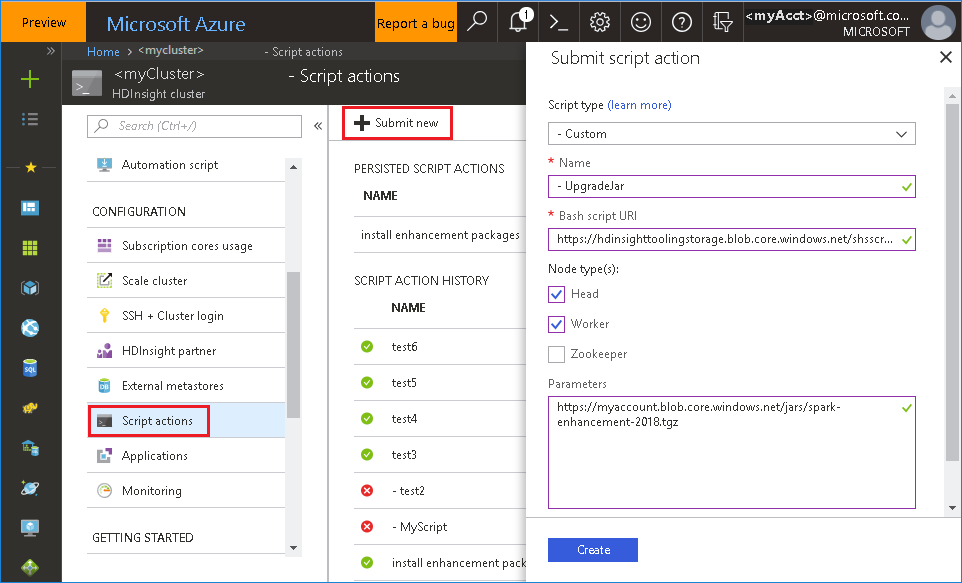
To hotfix with new version, use the script below which will download and update spark-enhancement.jar*.
Usage:
upgrade_spark_enhancement.sh https://${jar_path}
Example:
upgrade_spark_enhancement.sh https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.tgz
To run the bash file from Azure portal
- Launch Azure Portal, and select your cluster.
-
Click Script actions, then Submit new. Complete the Submit script action form, then click Create button.
- Script type: select Custom.
- Name: specify a script name.
- Bash script URI: upload the bash file to private cluster then copy URL here. Alternatively, use the URI provided.
https://hdinsighttoolingstorage.blob.core.windows.net/shsscriptactions/upgrade_spark_enhancement.sh- Check on Head and Worker.
- Parameters: set the parameters follow the bash usage.
2. Revert to community version of Spark history server
To revert to community version, do the following:
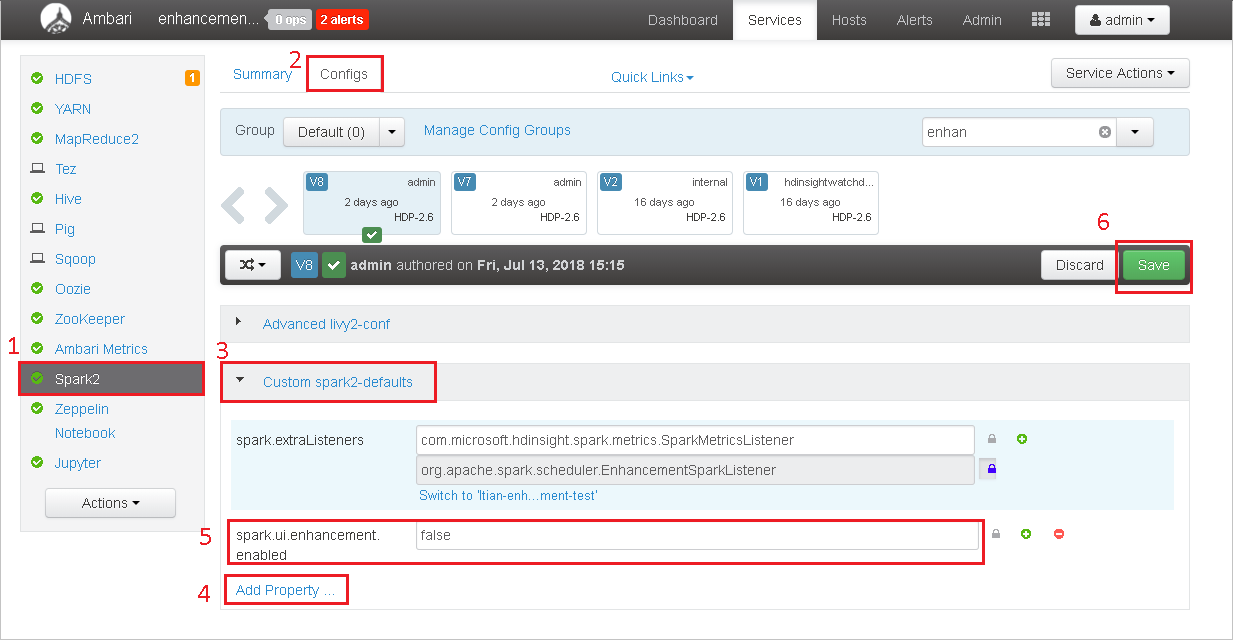
- Open cluster in Ambari. Click Spark2 in left panel.
- Click Configs tab.
- Expand the group Custom spark2-defaults.
- Click Add Property, add spark.ui.enhancement.enabled=false, save.
- The property sets to false now.
-
Click Save to save the configuration.
-
Click Spark2 in left panel, under Summary tab, click Spark2 History Server.
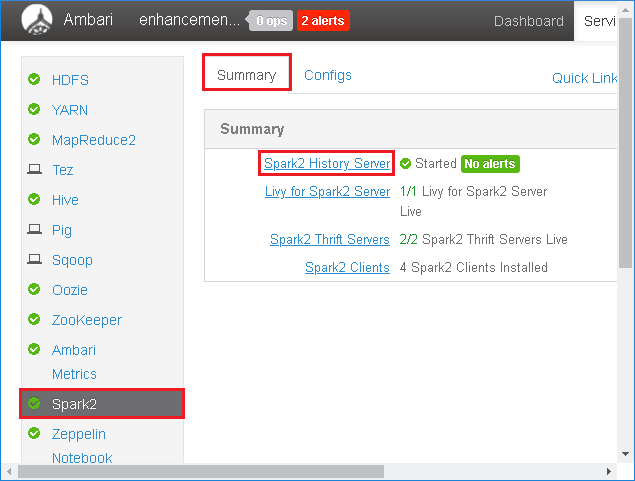
-
Restart history server by clicking Restart of Spark2 History Server.
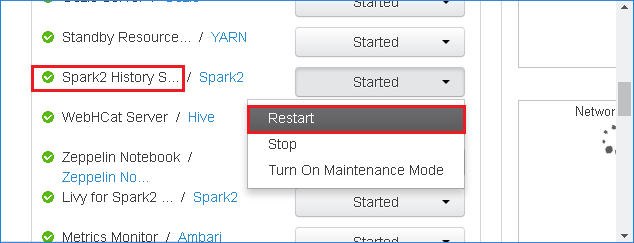
- Refresh the Spark history server web UI, it will be reverted to community version.
3. Collect history server events for diagnosis
If you run into history server error, follow the steps below to collect the Spark event:
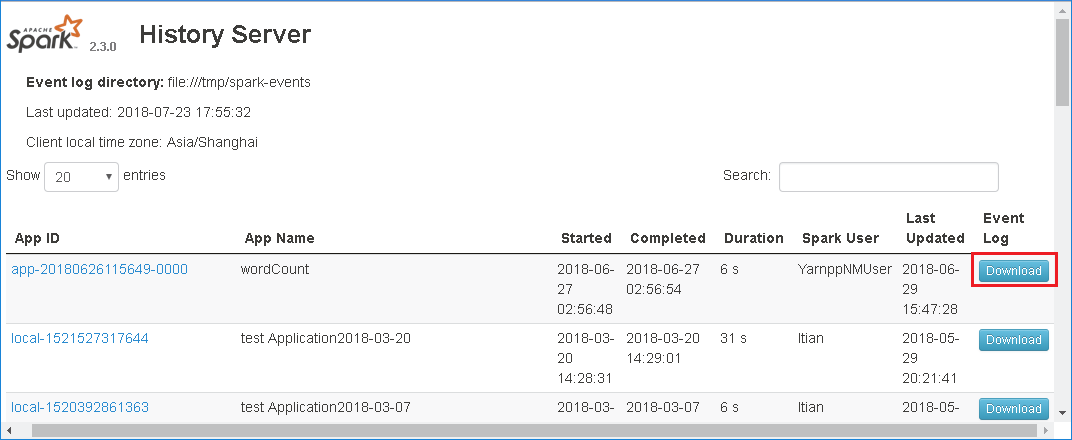
-
Download event by clicking Download in history server web UI.
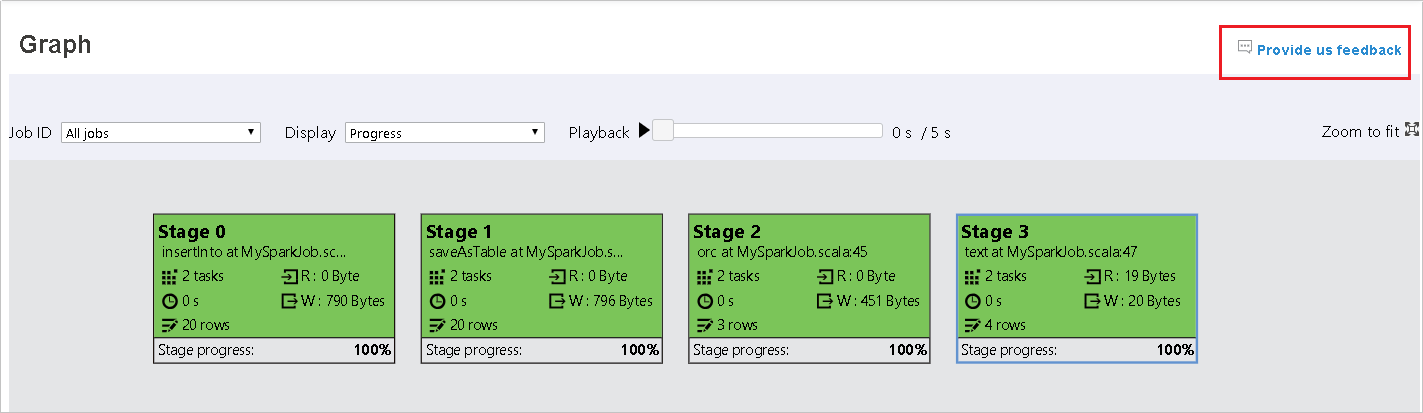
-
Click Provide us feedback from data/graph tab.
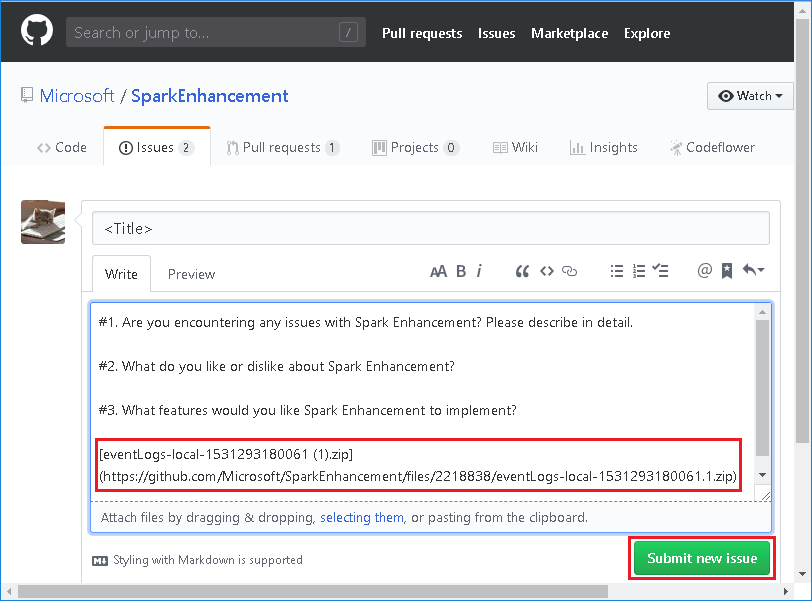
-
Provide the title and description of error, drag the zip file to the edit field, then click Submit new issue.
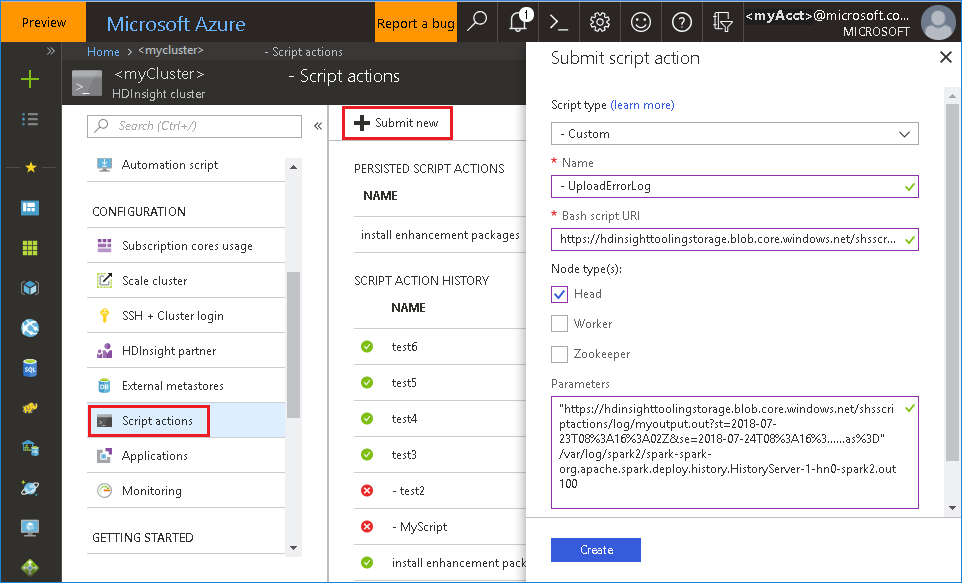
4. Upload history server log using script action
If you run into history server error, use the script below which will upload the history server log to the blob storage specified by us (who is working on investigating the history server issues).
Usage:
upload_shs_log.sh "${blob_link}" ${log_path} ${log_max_MB_size}
Example:
upload_shs_log.sh "https://${account_name}.blob.core.windows.net/${blob_container}/${log_file}{SAS_query_string}" /var/log/spark2/spark-spark-org.apache.spark.deploy.history.HistoryServer-1-{head_node_alias}-spark2.out 100
For head_node_alias, it may be hn0 or hn1 for a cluster with two head nodes. Fill in the active head node alias.
For log_file, specify by customer.
For SAS_query_string, you can get it from ASE:
-
Right-click the container you want to use and choose Get Shared Access Signature…:
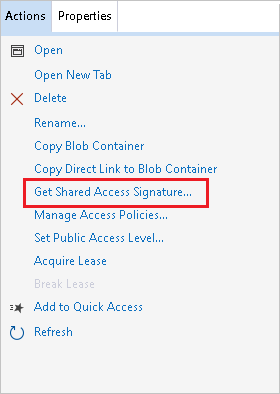
-
Choose permissions with Write and adjust the Start time and Expiry time:
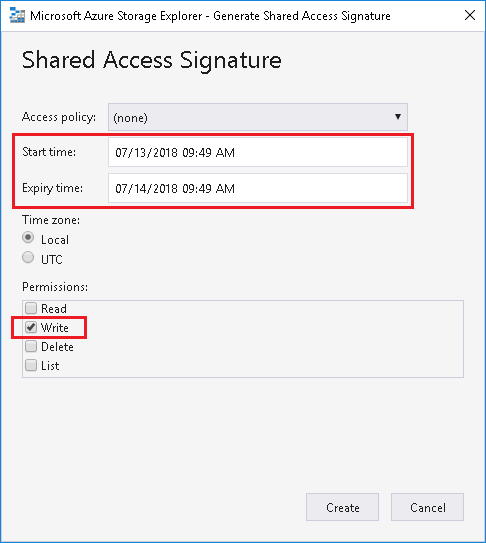
-
Click Copy to copy the query string:
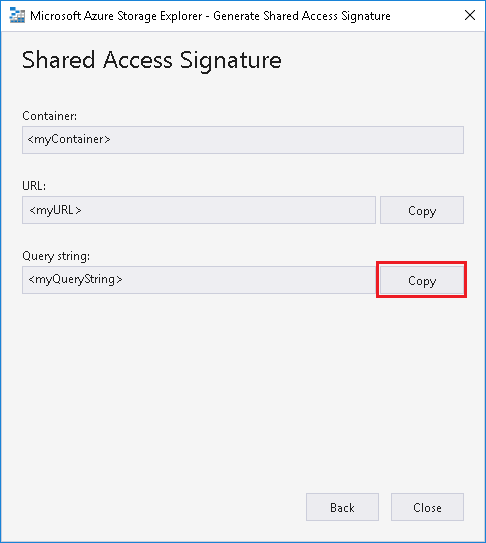
To run the bash file from Azure portal
- Launch Azure Portal, and select your cluster.
-
Click Script actions, then Submit new. Complete the Submit script action form, then click Create button.
- Script type: select Custom.
- Name: specify a script name.
- Bash script URI: upload the bash file to private cluster then copy URL here. Alternatively, use the URI provided.
https://hdinsighttoolingstorage.blob.core.windows.net/shsscriptactions/upload_shs_log.sh- Check on Head.
- Parameters: set the parameters follow the bash usage.